
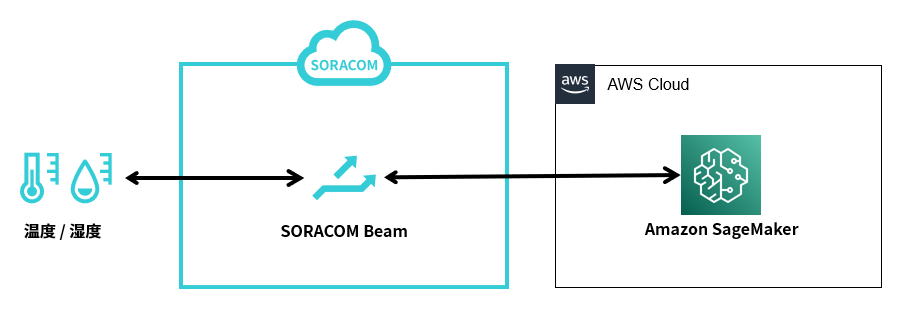
お客様の AWS アカウントにある Amazon SageMaker にデプロイしたモデルでの推論を、Beam が動作する SORACOM の AWS アカウントにのみ許可できます。
Beam の Web サイトエントリポイント を利用することで、Amazon SageMaker で推論するための認証情報を、デバイスにインストールする必要がなくなります。デバイスでは、以下のように Beam のエントリポイントを指定してアクセスするだけで、Amazon SageMaker で推論できます。
このページでは、例として 2022 年 12 月の東京の電力需要実績値 (万 kW) (出典: 東京電力パワーグリッド (株)) と東京の気象データ (出典: 気象庁) を利用して、ある時刻の温湿度から電力需要を予測するモデルを XGBoost で作成し、デバイスからデータを送信して、推論を実行する方法を説明します。

米国西部 (オレゴン) (us-west-2) を利用してください
Amazon SageMaker は、動作確認が取れている米国西部 (オレゴン) (us-west-2) を利用してください。このページで紹介するコードの一部は、アジアパシフィック (東京) (ap-northeast-1) では動作しないことがわかっています。
ステップ 1: データ準備用の Amazon SageMaker ノートブックインスタンスを作成する
Beam に送信した温度データおよび湿度データを、転送する先になる Amazon S3 バケットを作成します。
米国西部 (オレゴン) (us-west-2) の Amazon SageMaker のノートブックインスタンス画面にアクセスします。
をクリックします。
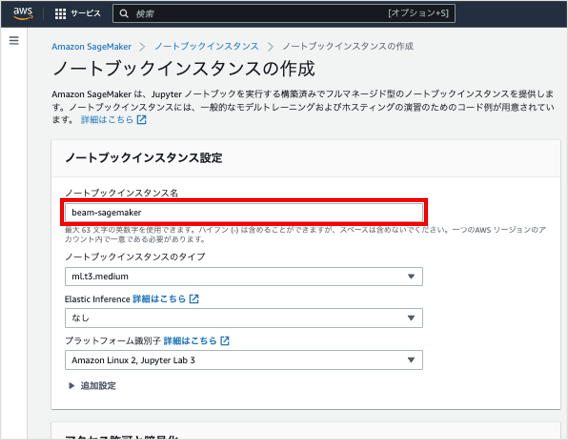
の に、ノートブックインスタンスの名前 (例: beam-sagemaker) を入力します。

の で、 をクリックします。
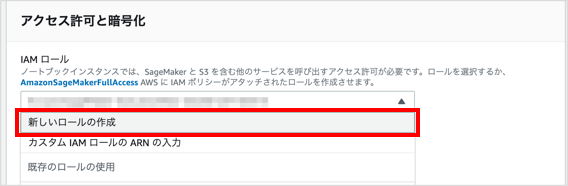

「IAM ロールを作成する」画面が表示されます。
で「任意の S3 バケット」が選択されていることを確認し、 をクリックします。
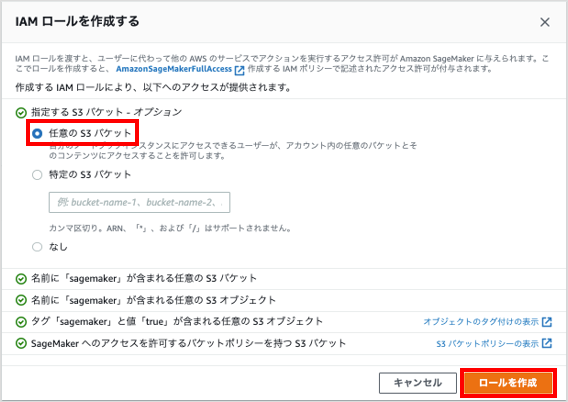

ノートブックインスタンスから SageMaker と S3 を利用するための IAM ロールが作成されます。
をクリックします。

ノートブックインスタンスの作成が開始されます。
に「InService」と表示されるまで待ちます。
ステップ 2: Jupyter Notebook でモデルを作成する
ステップ 1: データ準備用の Amazon SageMaker ノートブックインスタンスを作成する で作成したノートブックインスタンスを使って、モデルを作成します。
ノートブックインスタンス画面で、 に「InService」と表示されているノートブックインスタンスをクリックします。
ノートブックインスタンスの設定画面が表示されます。
をクリックします。
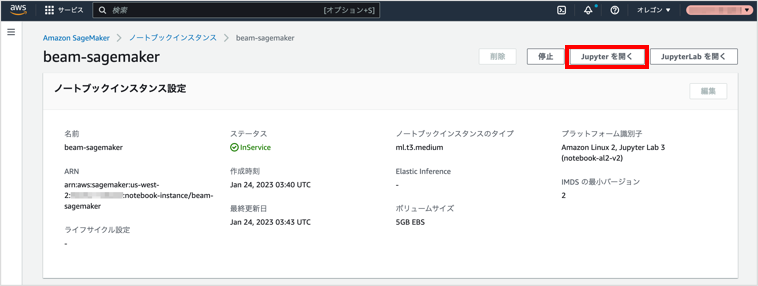

→ の順にクリックします。
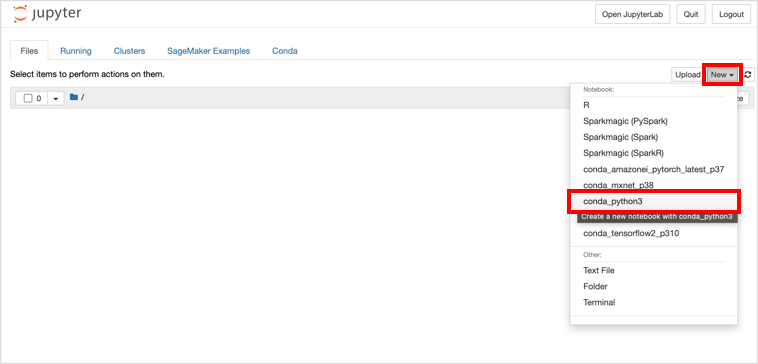

Jupyter Notebook が作成されます。
セルに以下のコードを貼り付けて、 をクリックします。
# import libraries import boto3, sagemaker import uuid, urllib.request, os import numpy as np import pandas as pd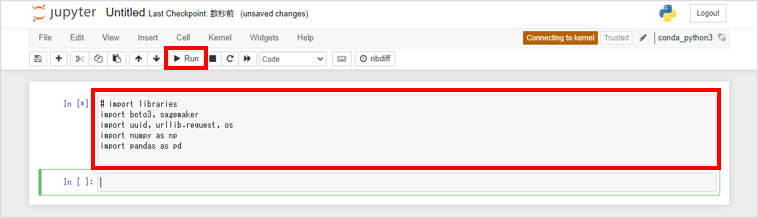

コードが実行され、このページで説明するコードの実行に必要なライブラリがインポートされます。
次のセルに以下のコードを貼り付けて、 をクリックします。
# Define IAM role role = sagemaker.get_execution_role() prefix = 'sagemaker/beam-xgboost' my_region = boto3.session.Session().region_name xgboost_container = sagemaker.image_uris.retrieve(framework="xgboost",region=my_region,version='1.5-1') print("my_region: " + my_region + ", xgboost_container: " + xgboost_container)コードが実行され、AWS リージョン (
my_region) とモデルの学習に利用するイメージの URL (xgboost_container) が表示されます。my_region: us-west-2, xgboost_container: 123456789012.dkr.ecr.us-west-2.amazonaws.com/sagemaker-xgboost:1.5-1Amazon SageMaker の XGBoost に対応した最新コンテナイメージは Docker Registry Paths and Example Code XGBoost (algorithm) を参照してください。
次のセルに以下のコードを貼り付けて、 をクリックします。
コードの 2 行目で、Amazon S3 バケットの名前を指定しています。必要に応じて変更してください。
bucket_name = 'beam-sagemaker-' + str(uuid.uuid4()) print("bucket_name: " + bucket_name) s3 = boto3.resource('s3') try: if my_region == 'us-east-1': s3.create_bucket(Bucket=bucket_name) else: s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region }) print('S3 bucket created successfully') except Exception as e: print('S3 error: ',e)「beam-sagemaker-XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX」という名前の Amazon S3 バケットが作成されます。
bucket_name: beam-sagemaker-XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX S3 bucket created successfully次のセルに以下のコードを貼り付けて、 をクリックします。
csv_filename = "weather_power_202212.csv" urllib.request.urlretrieve("https://users.soracom.io/ja-jp/docs/beam/aws-sagemaker/files/" + csv_filename, csv_filename) s3.Bucket(bucket_name).upload_file(csv_filename, csv_filename)weather_power_202212.csv (学習するサンプルデータ) がダウンロードされ、S3 バケットにアップロードされます。
weather_power_202212.csv は、2022 年 12 月の東京の電力需要実績値 (万 kW) (出典: 東京電力パワーグリッド (株)) と東京の気象データ (出典: 気象庁) を利用して作成したデータです。
次のセルに以下のコードを貼り付け、 をクリックします。
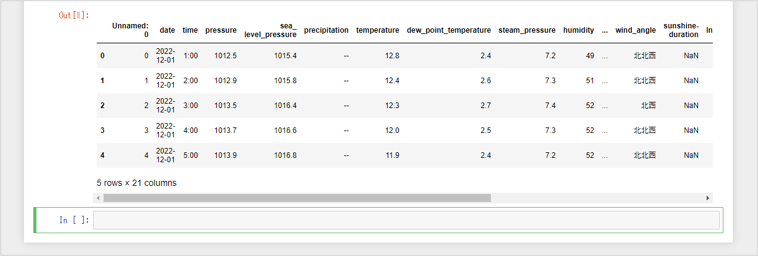
try: data_key = 'weather_power_202212.csv' data_location = 's3://{}/{}'.format(bucket_name, data_key) df_weather_power = pd.read_csv(data_location) print('Success: Data loaded into dataframe.') except Exception as e: print('Data load error: ',e) df_weather_power.head()S3 バケットにアップロードした weather_power_202212.csv (学習するサンプルデータ) が読み込まれ、表形式で表示されます。
学習するサンプルデータには、日付情報、気象データ、実績電気消費量がありますが、中でも を例として利用していきます。

次のセルに以下のコードを貼り付け、 をクリックします。
df_weather_power["time"]=df_weather_power["time"].str.replace(':00','').astype('int') train_data, test_data = np.split(df_weather_power.loc[:,["time","temperature","humidity", "actual_power"]].sample(frac=1, random_state=1729), [int(0.7 * len(df_weather_power))]) print(train_data.shape, test_data.shape)学習するサンプルデータが、学習データ (
train_data) とテストデータ (test_data) に分割されます。(520, 4) (223, 4)次のセルに以下のコードを貼り付け、 をクリックします。
pd.concat([train_data['actual_power'], train_data.drop(['actual_power'], axis=1)], axis=1).to_csv('train.csv', index=False, header=False) s3.Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv') s3_input_train = sagemaker.inputs.TrainingInput(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')学習データが S3 バケットにアップロードされます。
次のセルに以下のコードを貼り付け、 をクリックします。
sess = sagemaker.Session() xgb = sagemaker.estimator.Estimator(xgboost_container,role, instance_count=1, instance_type='ml.m5.xlarge',output_path='s3://{}/{}/output'.format(bucket_name, prefix),sagemaker_session=sess) xgb.set_hyperparameters(objective='reg:squarederror',num_round=100)Amazon SageMaker のトレーニングジョブが作成されます。
ここでは例として、Amazon XGBoost を利用して、与えられた「time (時間)」、「temperature (温度)」、「humidity (湿度 (%))」から、「actual_power (電力需要実績値 (万 kW))」を予測するように回帰モデルを学習します。
次のセルに以下のコードを貼り付け、 をクリックします。
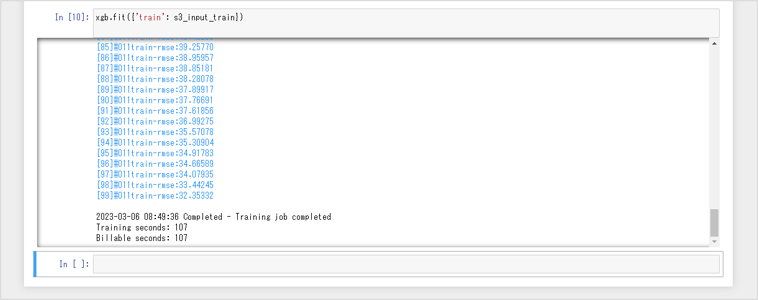
xgb.fit({'train': s3_input_train})トレーニングジョブが実行されます。終了までに数分かかる場合があります。
トレーニングジョブが終了すると、以下のように「Billable seconds: 999」と表示されます。

次のセルに以下のコードを貼り付け、 をクリックします。
from sagemaker.serverless import ServerlessInferenceConfig serverless_config = ServerlessInferenceConfig( memory_size_in_mb = 2048, max_concurrency = 5 ) serverless_predictor = xgb.deploy(serverless_inference_config = serverless_config)学習したモデルがサーバーレスエンドポイントにデプロイされ、エンドポイントの名前 (例:
sagemaker-xgboost-2023-03-06-08-53-15-937) が表示されます。エンドポイントの名前は、これ以降、${amazon_sagemaker_model_endpoint_name} と表記します。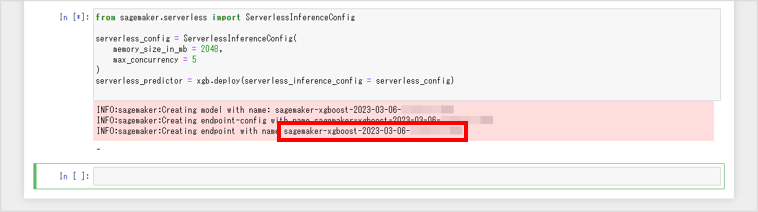

作成されたモデルは、Amazon SageMaker の モデル画面 にアクセスしても確認できます。

次のセルに以下のコードを貼り付け、 をクリックします。
from sagemaker.serializers import CSVSerializer test_data_array = test_data.drop(['actual_power'], axis=1).values serverless_predictor.serializer = CSVSerializer() prediction_results = serverless_predictor.predict(test_data_array).decode('utf-8') predictions = np.fromstring(prediction_results[1:], sep='\n') actual = test_data['actual_power'].to_numpy() RMSE = np.sqrt(np.mean(np.power(actual-predictions,2))) print(RMSE)テストデータで推論を実行し、予測精度を確認します。ここでは、推論した値と実際の値の RMSE (二乗平均平方根誤差) を計算しています。
364.0653729628472
ステップ 3: IAM ポリシーと IAM ロールを作成する
Beam の Web サイトエントリポイントが、お客様の AWS アカウントで作成したモデルでの推論を実行するために、お客様の AWS アカウントに以下の設定の IAM ポリシーと IAM ロールを作成します。操作手順について詳しくは、IAM ポリシーと IAM ロールを作成する を参照してください。
| 項目 | 説明 |
|---|---|
| IAM ポリシー | このページで説明する機能を体験するために、お客様の AWS アカウントで作成したモデルでの推論を実行する権限を追加した IAM ポリシーを作成します。 具体的には以下のように設定します。
|
| IAM ロール | このページで説明する機能を体験するために、「SORACOM の AWS アカウント」を信頼できるエンティティとして指定した IAM ロールを作成します。 具体的には以下のように設定します。
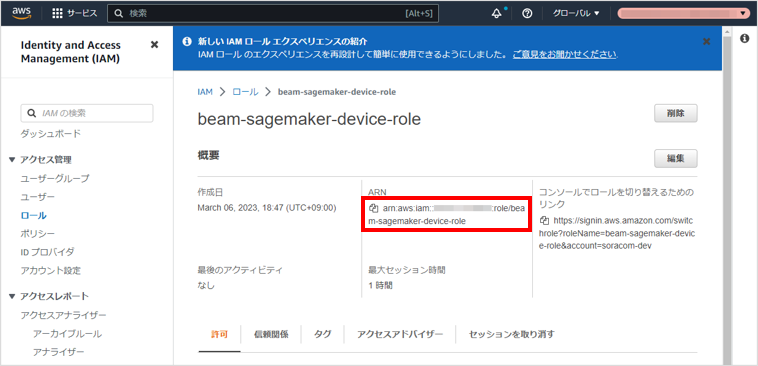
なお、ここで作成した IAM ロールの ARN を、これ以降、${iam_role_arn} と表記します。例:
|

ステップ 4: SORACOM Beam をセットアップする
Beam の Web サイトエントリポイントを設定します。ここで説明するとおりに設定すると、以下の機能が実現できます。
- IoT SIM を利用するデバイスから Amazon SageMaker のモデルにデータを送信して、推論する。
認証情報ストアに AWS IAM ロール認証情報を登録する
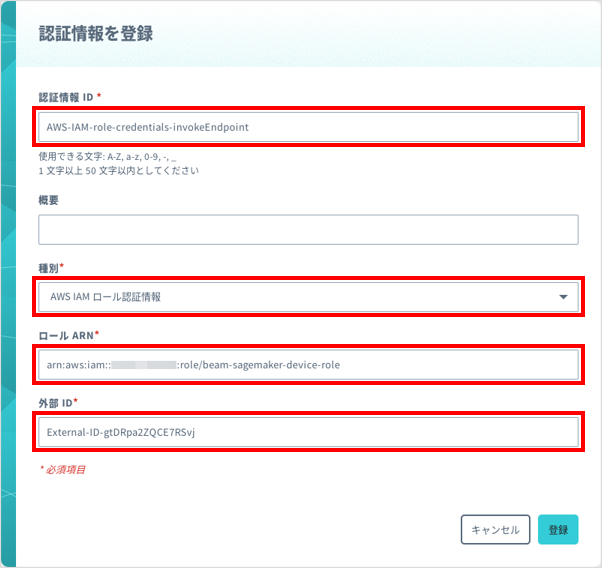
Beam から Amazon SageMaker のエンドポイントを呼び出すために、IAM ロールに関する認証情報を、SORACOM ユーザーコンソールに登録します。
具体的には、認証情報ストアの「認証情報を登録」画面で以下のように登録します。この画面の表示方法については、認証情報を登録する を参照してください。
| 項目 | 説明 |
|---|---|
認証情報を識別するために任意の名前を入力します。例: AWS-IAM-role-credentials-invokeEndpoint | |
| 「AWS IAM ロール認証情報」を選択します。 | |
${iam_role_arn} を入力します。例: arn:aws:iam::XXXXXXXXXXXX:role/beam-sagemaker-device-role | |
${external_id} を入力します。例: External-ID-gtDRpa2ZQCE7RSvj |

Beam の Web サイトエントリポイントを設定する
Beam の設定はグループに対して行います
ここでは、グループの設定を変更する操作のみを説明します。グループの仕組みやグループを作成する操作について詳しくは、グループ設定 を参照してください。
SIM グループ画面で をクリックします。
SIM グループ画面を表示する操作について詳しくは、グループの設定を変更する を参照してください。
→ の順にクリックします。
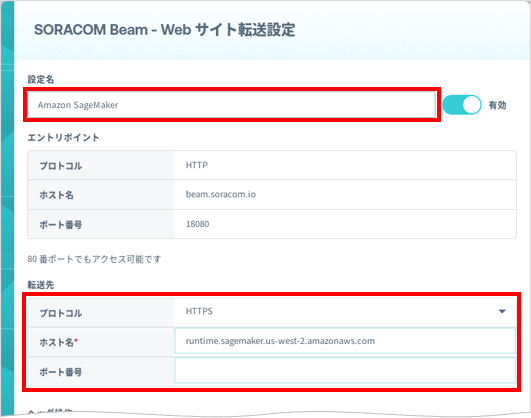
「SORACOM Beam - Web サイト転送設定」画面が表示されます。
以下のように設定します。
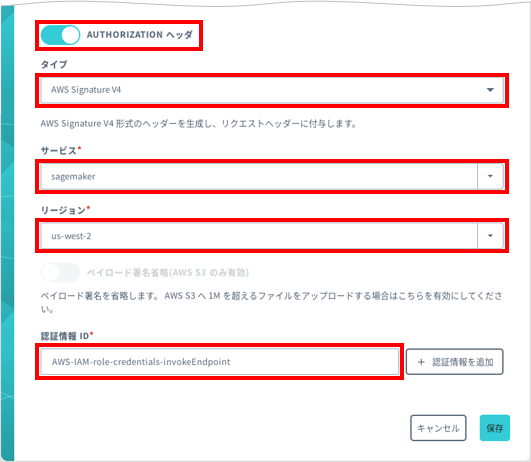
項目 説明 任意の設定名 (例: Amazon SageMaker) を入力します。→ 「HTTPS」を選択します。 → 「runtime.sagemaker.us-west-2.amazonaws.com」を入力します。 → 空欄のままにします。 → オンにして、以下のように設定します。
- : 「AWS Signature V4」を選択します。
- : 「Amazon SageMaker」を選択します。
- : Amazon SageMaker のリージョン「us-west-2」(米国西部 (オレゴン)) を選択します。
- : 認証情報ストアに AWS IAM ロール認証情報を登録する で登録した AWS IAM ロール認証情報を選択します。


Web サイトエントリポイントの設定値の意味は、Web サイトエントリポイント を参照してください。
をクリックします。
IoT SIM の Beam の設定が完了しました。
ステップ 5: Web サイトエントリポイントを使用して Amazon SageMaker にデプロイしたモデルにデータを送信して推論する
Beam の Web サイトエントリポイントを使用して、Amazon SageMaker にデプロイしたモデルにデータを送信して、推論します。
AWS SDK for Python (Boto3) を使用して推論する
デバイスに、AWS SDK for Python (Boto3) をインストールします。
$ pip install boto3デバイスに、sagemaker_invoke_endpoint.py をダウンロードします。
$ wget http://users.soracom.io/ja-jp/docs/beam/aws-sagemaker/files/sagemaker_invoke_endpoint.pysagemaker_invoke_endpoint.py はサンプルスクリプトです
sagemaker_invoke_endpoint.py は、AWS SDK for Python (Boto3) を利用して、Amazon SagaMaker にデプロイしたモデルで推論する機能を持つサンプルスクリプトです。
デバイスで、以下のコマンドを実行します。
$ python -c "import sagemaker_invoke_endpoint;\ sagemaker_invoke_endpoint.invoke_endpoint(\ endpoint_name='sagemaker-xgboost-2023-03-06-08-53-15-937',\ hour=9,\ temperature=9.0,\ humidity=81)"sagemaker_invoke_endpoint.invoke_endpoint()メソッドの引数は以下のとおりです。項目 説明 endpoint_nameデプロイしたモデルのエンドポイント名 ${amazon_sagemaker_model_endpoint_name} を指定します。例: sagemaker-xgboost-2023-03-06-08-53-15-937hour温度と湿度が計測された時間を指定します。例: 9(9 時)temperature温度を指定します。例: 9.0humidity湿度 (%) を指定します。例: 81.0成功すると電力需要 (万 kW) の値が推論結果として表示されます。
{'predictions': [{'score': 3453.01220703125}]}
curl コマンドを使用してデータを送信して推論する
IoT SIM を利用するデバイスで、以下のコマンドを実行しても、データを送信して推論できます。
$ curl -X POST --data "${hour},${temperature},${humidity}" -H "Content-Type: text/csv" -H "Accept: application/json" http://beam.soracom.io:18080/endpoints/${amazon_sagemaker_model_endpoint_name}/invocations
例:
$ curl -X POST --data "9,9.0,81.0" -H "Content-Type: text/csv" -H "Accept: application/json" http://beam.soracom.io:18080/endpoints/sagemaker-xgboost-2023-03-06-08-53-15-937/invocations
{'predictions': [{'score': 3453.01220703125}]}
curl で実行する場合は HTTP エントリポイントも利用できます
HTTP エントリポイント の → に、「/endpoints/${amazon_sagemaker_model_endpoint_name}/invocations」(例: /endpoints/sagemaker-xgboost-2023-03-06-08-53-15-937/invocations) を指定すると、HTTP エントリポイントにデータを送信しても推論を実行できます。
(参考) SageMaker の利用を終了する
SageMaker が不要になった場合は、作成したデータを削除します。
ステップ 2: Jupyter Notebook でモデルを作成する で作成した Jupyter Notebook の次のセルに以下のコードを貼り付けて、 をクリックします。
serverless_predictor.delete_model() serverless_predictor.delete_endpoint()デプロイされたモデルが削除されます。Amazon SageMaker の モデル画面 にアクセスして、削除されたことを確認してください。
同様に、このページで作成した以下の情報も削除してください。
- AWS
- SageMaker のノートブックインスタンス
- Amazon S3 バケット
- IAM ロール
- ノートブックインスタンスから SageMaker と S3 を利用するための IAM ロール
- SORACOM の AWS アカウントから SageMaker を利用するための IAM ロール
- IAM ポリシー
- SORACOM ユーザーコンソール
- 認証情報
- グループ
- デバイス
- sagemaker_invoke_endpoint.py
- AWS